
DreamPoster can generate a wide variety of posters. Note that all input images are generated by Seedream3.0.

DreamPoster can generate a wide variety of posters. Note that all input images are generated by Seedream3.0.
We present DreamPoster, a text-to-image generation framework that intelligently synthesizes high-quality posters from user-provided images and text prompts while maintaining content fidelity and supporting flexible resolution and layout outputs. Specifically, DreamPoster is built upon our T2I model Seedream3.0 to uniformly process different poster generating types. For dataset construction, we propose a systematic data annotation pipeline that precisely annotates textual content and typographic hierarchy information within poster images, while employing comprehensive methodologies to construct paired datasets comprising source materials (e.g., raw graphics/text) and their corresponding final poster outputs. Additionally, we implement a progressive training strategy that enables the model to hierarchically acquire multi-task generation capabilities while maintaining high-quality generation. Evaluations on our testing benchmarks demonstrate DreamPoster's superiority over existing methods, achieving a high usability rate of 88.55%, compared to GPT4o (47.56%) and SeedEdit3.0 (25.96%). DreamPoster will be online in Jimeng and other Bytedance Apps.

We collect a large and diverse dataset of high-quality posters which annotated by our proposed data curation pipeline. We first filter the collected data by OCR and aestheic score to obtain a clean poster dataset with recognizable text and high image quality. Specifically, we train a Poster Captioner that specifically processes text-heavy posters, achieving accurate identification and description of textual attributes including font size, typeface, color schemes, and layout information. The Poster Captioner re-caption each poster with a glyph-focused caption and a layout-focused caption, which enables DreamPoster to learn both fine-grained glyphs and typographical hierachy. To establish paired datasets comprising source images and target poster counterparts, we implement a systematic framework leveraging a suite of advanced image processing methodologies, including context-aware inpainting, semantic segmentation, traditional rendering, etc., to extract and refine source visual content derived from high-quality poster images. This pipeline ensures structural correspondence while preserving semantic fidelity between source-target pairs through controlled image transformations.
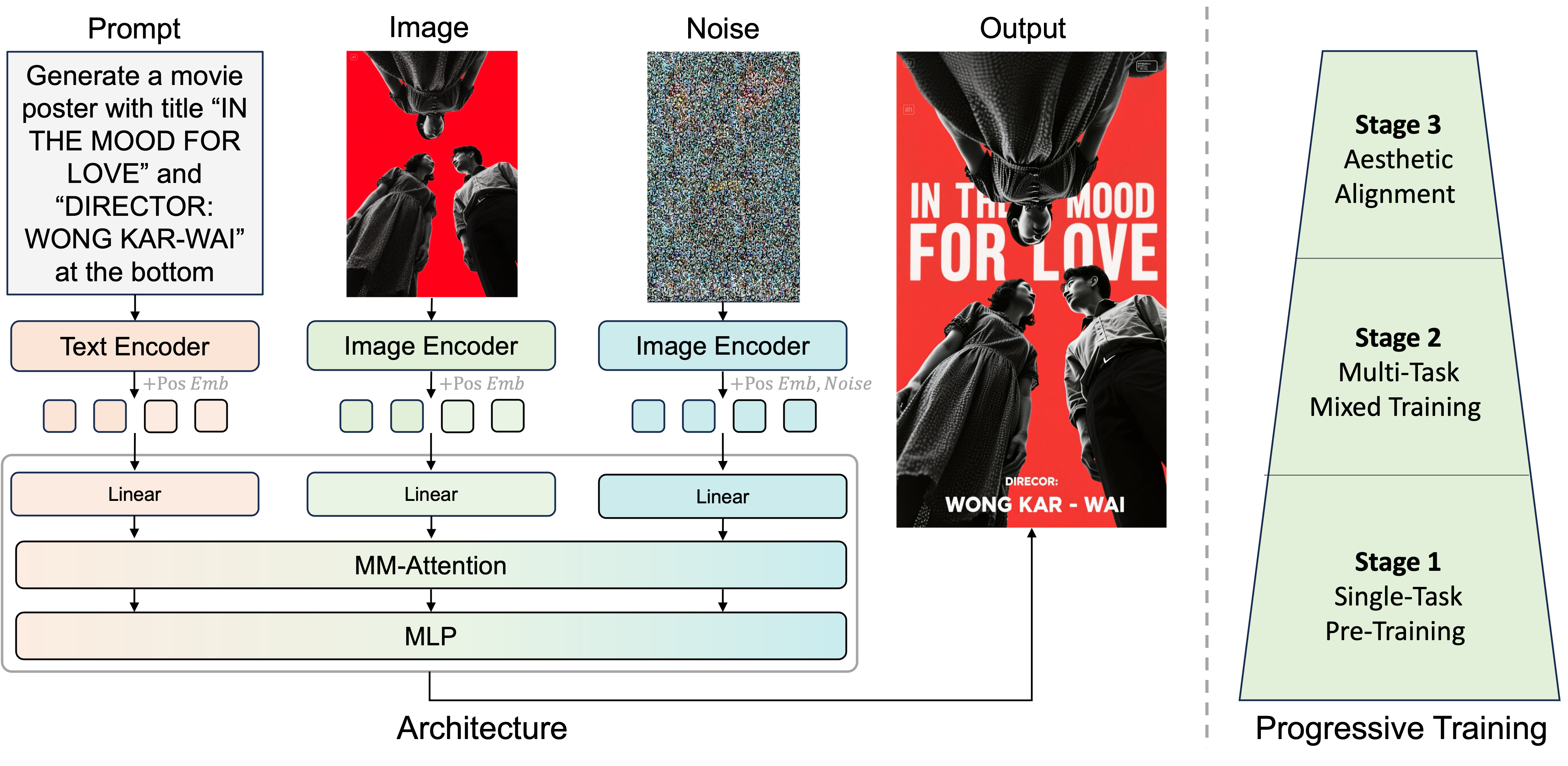
DreamPoster employs a multi-modal architecture that seamlessly integrates text and image information. We concatenate text tokens, condition image tokens and noise tokens along sequence dimension with respective position embeddings. When training, we finetune certain layers in DiT and adopt a progressive three-stage training strategy to gradually improve the model's design capabilities at multiple levels: Stage 1: Single-task Pretraining - In this phase, the model is trained only on the task of adding text to images. The goal is to learn the basic fusion of image and text information. This helps the model grasp fundamental connections between images and text. Stage 2: Multi-task Mixed Training - The model is further trained on mixed tasks such as text modification, deletion, and poster stylization etc., expanding its ability to handle more complex and varied scenarios. Stage 3: Fine-grained Aesthetic Alignment - In the final stage, the model is fine-tuned with a small batch of high-quality data. This enables it to process more intricate design elements and optimize layout relationships and spatial usage, achieving fine control over design details. Through these three stages of progressive training, the model is optimized to varying degrees at each stage, ultimately achieving high-quality, professional poster generation.
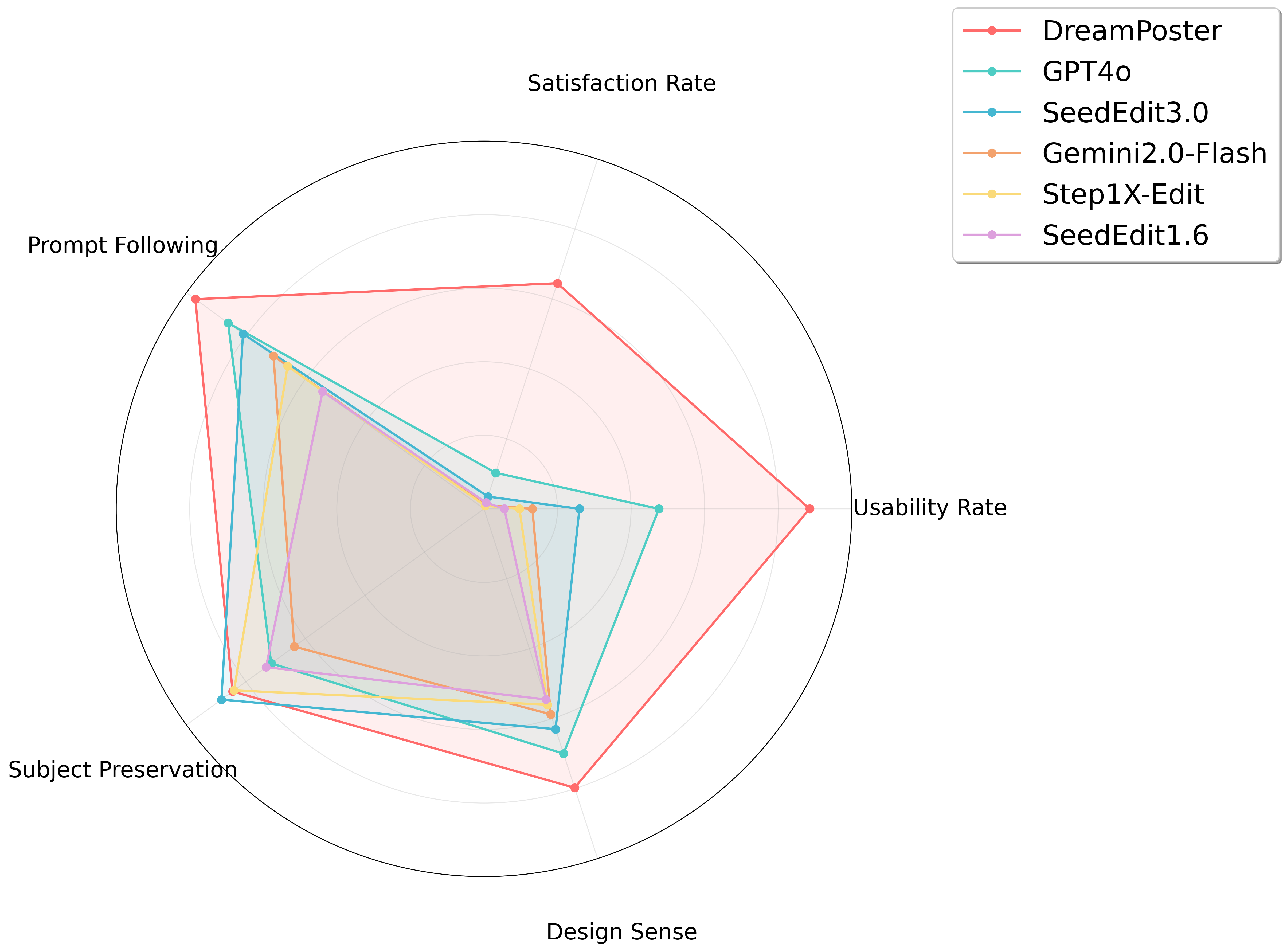
We conduct comprehensive human evaluation comparing DreamPoster with state-of-the-art baselines across three key dimensions: Prompt Following, Subject Preservation, and Design Sense. DreamPoster outperforms exsiting models by a clear margin. We also conduct a usability evaluation involving 60 human evaluators, with quantitative analysis revealing that DreamPoster achieves statistically superior usability rates (88.55%) compared to state-of-the-art baselines.

Note that GPT-4o and Gemini2.5 exhibits instability in aspect ratio preservation during image synthesis, while Step1X-Edit and SeedEdit1.6 enforces rigid input-output dimensional alignment through fixed aspect ratio constraints.